
I am Hassan Taherian, currently pursuing my PhD in Computer Science at Ohio State University since 2017. I have the privilege of conducting my research under the guidance of Prof. DeLiang Wang. My research interests span a variety of domains in the world of sound and speech processing:
- Speech Separation and Enhancement
- Sound Event Detection and Sound Localization
- Automatic Speech Recognition
- Speaker Recognition and Diarization
- Speech Synthesis
- Deep Learning in Audio Processing
Research Highlights
Conversational Speaker Separation via Neural Diarization
We introduce a new framework, termed ``speaker separation via neural diarization" (SSND), for multi-channel conversational speaker separation. The proposed SSND framework achieves state-of-the-art diarization and ASR results, surpassing all existing methods on the open LibriCSS dataset. Read More
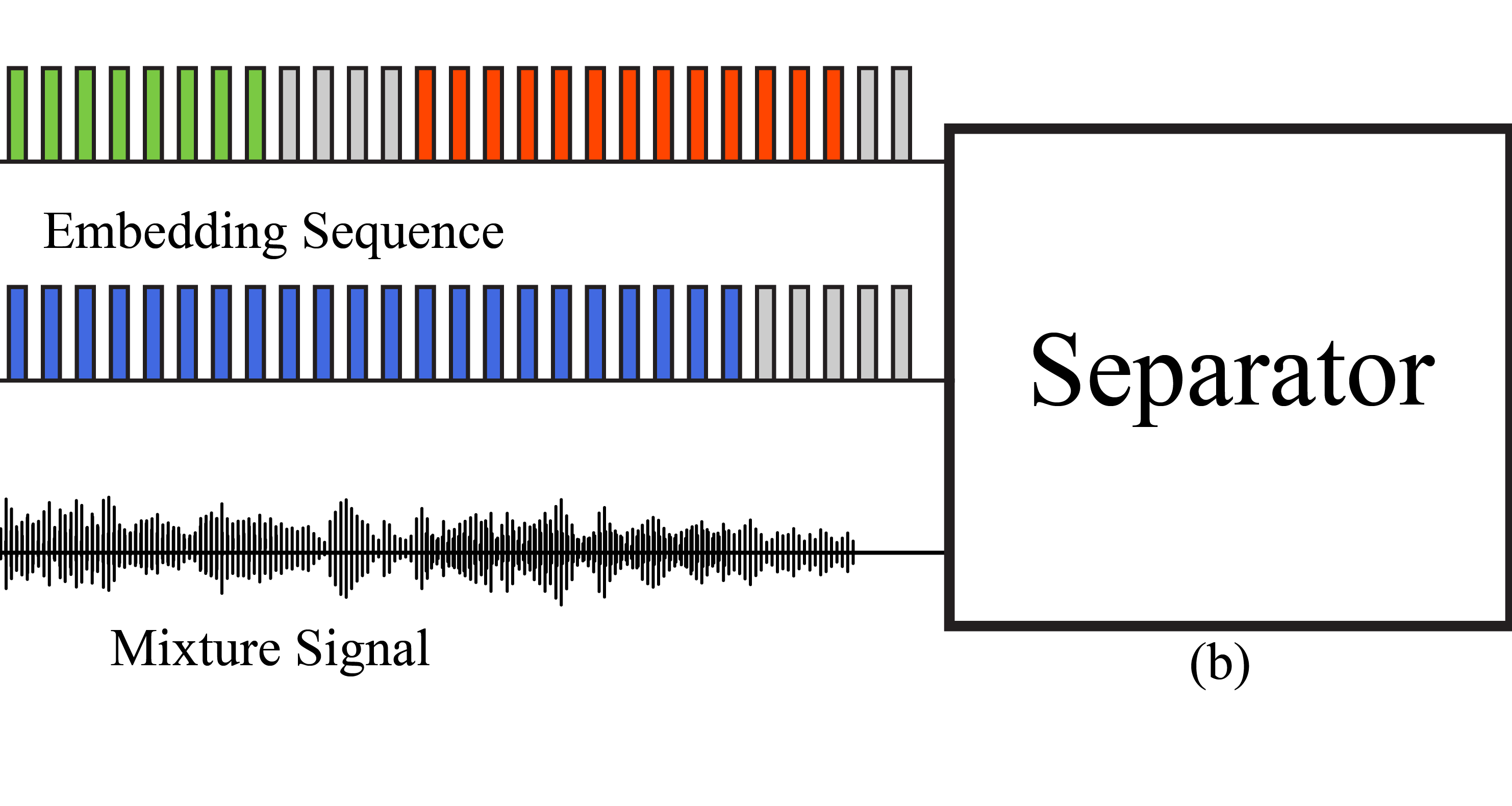
Location-based Training (LBT)
We have proposed two novel training criteria to address the permutation ambiguity problem for multi-channel talker-independent speaker separation. Different from widely-used permutation invarient trainig (PIT), the new criteria organize DNN outputs on the basis of speaker azimuths and distances relative to a microphone array. Read More

Microphone Array Geometry Agnostic Modeling
We utilized spatial features along with speaker embeddings for personalized speech enhancement (PSE) and showed their combination significantly improved the performance for both ASR and signal quality. Furthermore, we proposed a new architecture and introduced the stream pooling layer to perform multi-channel PSE with any number and arrangement of microphones in a way where the output is invariant to the microphone order. Our proposed model consistently outperformed the geometry-dependent models. Read More

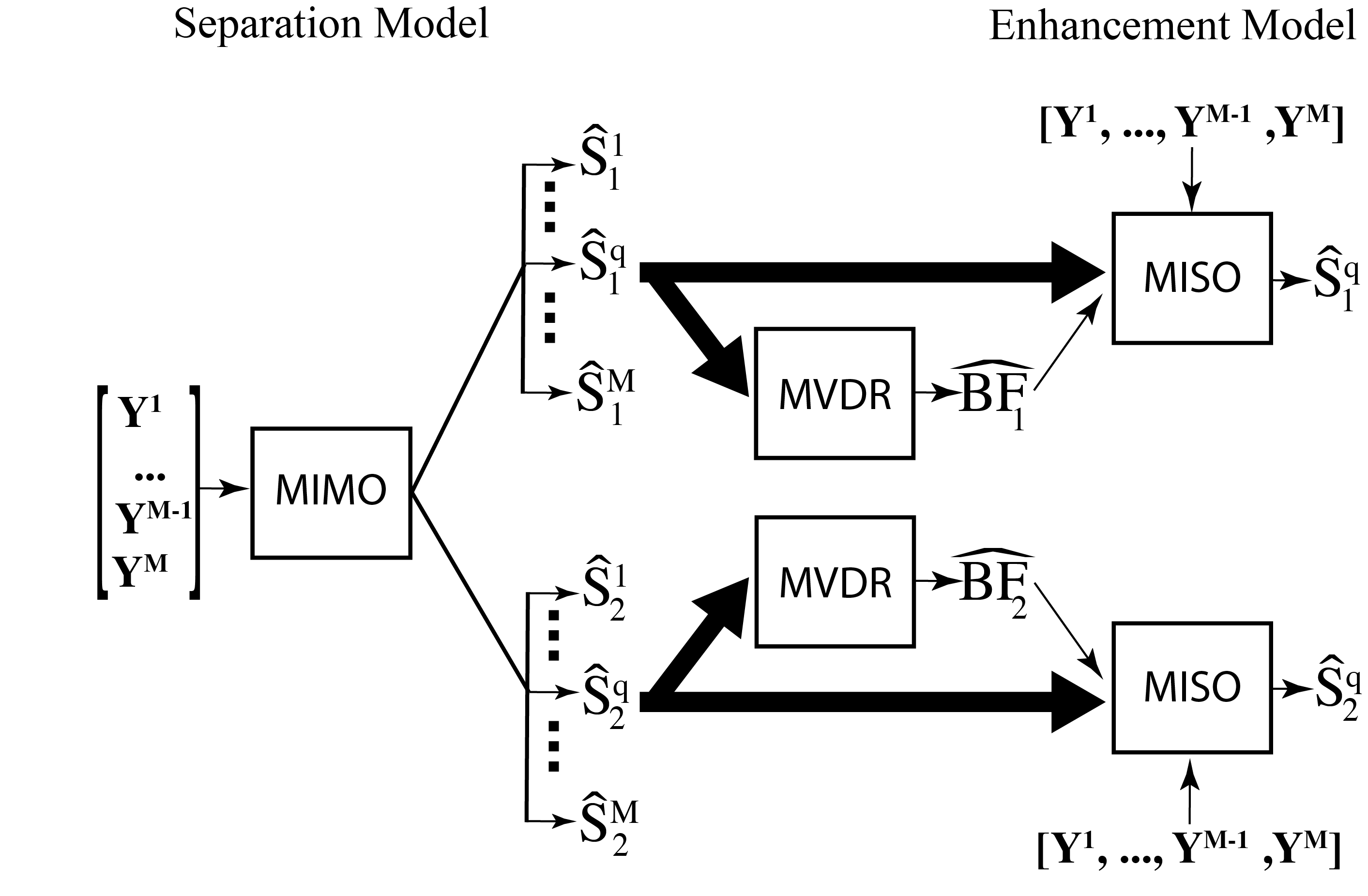
Multi-input Multi-output Complex Spectral Mapping
Current deep learning based multi-channel speaker separation methods produce a monaural estimate of speaker signals captured by a reference microphone. This work presents a new multi-channel complex spectral mapping approach that simultaneously estimates the real and imaginary spectrograms of all speakers at all microphones. Experimental results show that the proposed MIMO separation model outperforms a multi-input single-output (MISO) speaker separation model with monaural estimates. The proposed approach achieves the state-of-the-art speaker separation on the open LibriCSS dataset. Read More
Publications
- Leveraging Sound Localization to Improve Continuous Speaker Separation, to apprear at ICASSP’24
Hassan Taherian, Ashutosh Pandey, Daniel Wong, Buye Xu, and DeLiang Wang - Multi-channel conversational speaker separation via neural diarization, * submitted to IEEE/ACM TASLP* [pdf]
Hassan Taherian and DeLiang Wang - Multi-input multi-output complex spectral mapping for speaker separation, Interspeech’23 [pdf]
Hassan Taherian, Ashutosh Pandey, Daniel Wong, Buye Xu, and DeLiang Wang - Multi-resolution Location-based training for multi-channel continuous speech separation, ICASSP’23 [pdf]
Hassan Taherian and DeLiang Wang - Breaking the trade-off in personalized speech enhancement with cross-task knowledge distillation, ICASSP’23 [pdf]
Hassan Taherian Sefik Emre Eskimez, and Takuya Yoshioka - Multi-channel talker-independent speaker separation through location-based training, IEEE/ACM TASLP’22 [pdf]
Hassan Taherian, Ke Tan, and DeLiang Wang - One model to enhance them all: array geometry agnostic multi-channel personalized speech enhancement, ICASSP’22 [pdf]
Hassan Taherian, Sefik Emre Eskimez, Takuya Yoshioka, Huaming Wang, Zhuo Chen, and Xuedong Huang - Location-based training for multi-channel talker-independent speaker separation, ICASSP’22 [pdf]
Hassan Taherian, Ke Tan, and DeLiang Wang - A causal and talker-independent speaker separation/dereverberation deep learning algorithm: Cost associated with conversion to real-time capable operation, JASA’21 [pdf]
Eric W. Healy, Hassan Taherian, Eric M. Johnson, and DeLiang Wang - Deep learning based speaker separation and dereverberation can generalize across different languages to improve intelligibility, JASA’21 [pdf]
Eric W. Healy, Eric M. Johnson, Masood Delfarah, Divya S. Krishnagiri, Victoria A. Sevich, Hassan Taherian, and DeLiang Wang - Time-domain loss modulation based on overlap ratio for monaural conversational speaker separation, ICASSP’21 [pdf]
Hassan Taherian and DeLiang Wang - Robust speaker recognition based on single-channel and multi-channel speech enhancement, IEEE/ACM TASLP’20 [pdf]
Hassan Taherian, Zhong-Qiu Wang, Jorge Chang, and DeLiang Wang - Deep learning based multi-channel speaker recognition in noisy and reverberant environments, Interspeech’19 [pdf]
Hassan Taherian, Zhong-Qiu Wang, and DeLiang Wang
Patents
Hassan Taherian, Jonathan Huang and Carlos M. Avendano, Method and System for Detecting Sound Event Liveness Using a Microphone Array, U.S. Patent No. 11,533,577. 20 Dec. 2022. [Google Patents]
Hassan Taherian, Sefik Emre Eskimez, Takuya Yoshioka, Huaming Wang, Zhuo Chen and Xuedong Huang, Array Geometry Agnostic Multi-channel Personalized Speech Enhancement, U.S. Patent App. No. US20230116052A1, Dec 2021.
Research Experience
 Ohio State University
Ohio State University
- Research Assistant, Perception and Neurodynamics Laboratory, May 2018 – Present
 Microsoft Research
Microsoft Research
- Research Intern, Azure Cognitive Services, May 2022 – August 2022
- Research Intern, Azure Cognitive Services, May 2021 – August 2021
 Apple Inc.
Apple Inc.
- Research Intern, Interactive Media Group, June 2020 – August 2020
Teaching Experience
Ohio State University
Instructor of CSE 1222 - Programming in C++ Responsible for teaching, grading and holding office hours Offered in Spring 2018, and Fall 2017 (~40 enrollment)